Decoding Vector Embeddings: Empowering AI with Data Representation
How numerical vectors convert raw data into actionable insights
Introduction
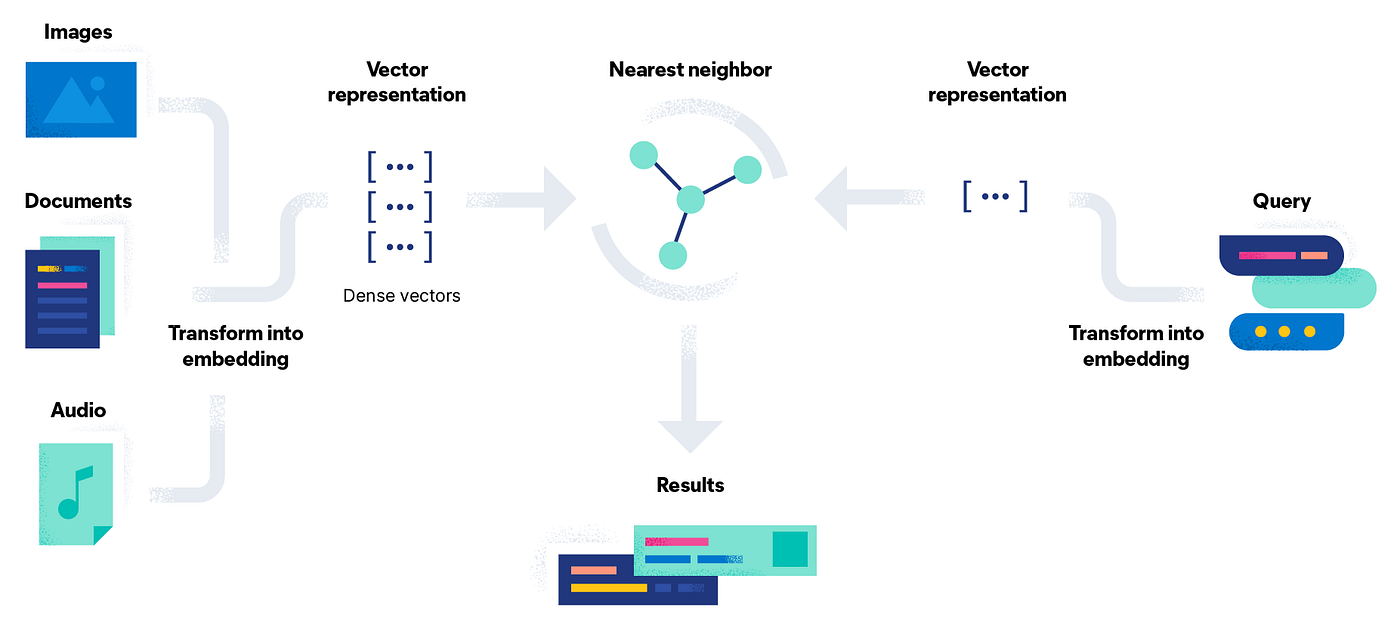
Vector embedding is a powerful technique in the field of machine learning and data representation, enabling the conversion of complex data points into numerical vectors. This conversion allows for the capture of essential features and attributes of the data, facilitating similarity calculations, clustering, and classification tasks.
In this article, we will explore the concept of vector embedding, its applications across different domains, and the methods used to create meaningful vector representations of data.
What are Vector Embeddings?
Vector embeddings provide a method for transforming words, sentences, and other data into numerical representations that encapsulate their semantic meaning and associations.
By mapping diverse data types as points in a multi-dimensional space, vector embeddings facilitate the clustering of similar data points, enabling machines to comprehend and process this data with greater efficiency.
Types of Vector Embedding
Vector embeddings play a crucial role in enabling machine learning algorithms to discern patterns in data and execute tasks such as sentiment analysis, language translation, recommendation systems, and various other applications. Various applications commonly utilize a range of vector embeddings, each serving distinct purposes.
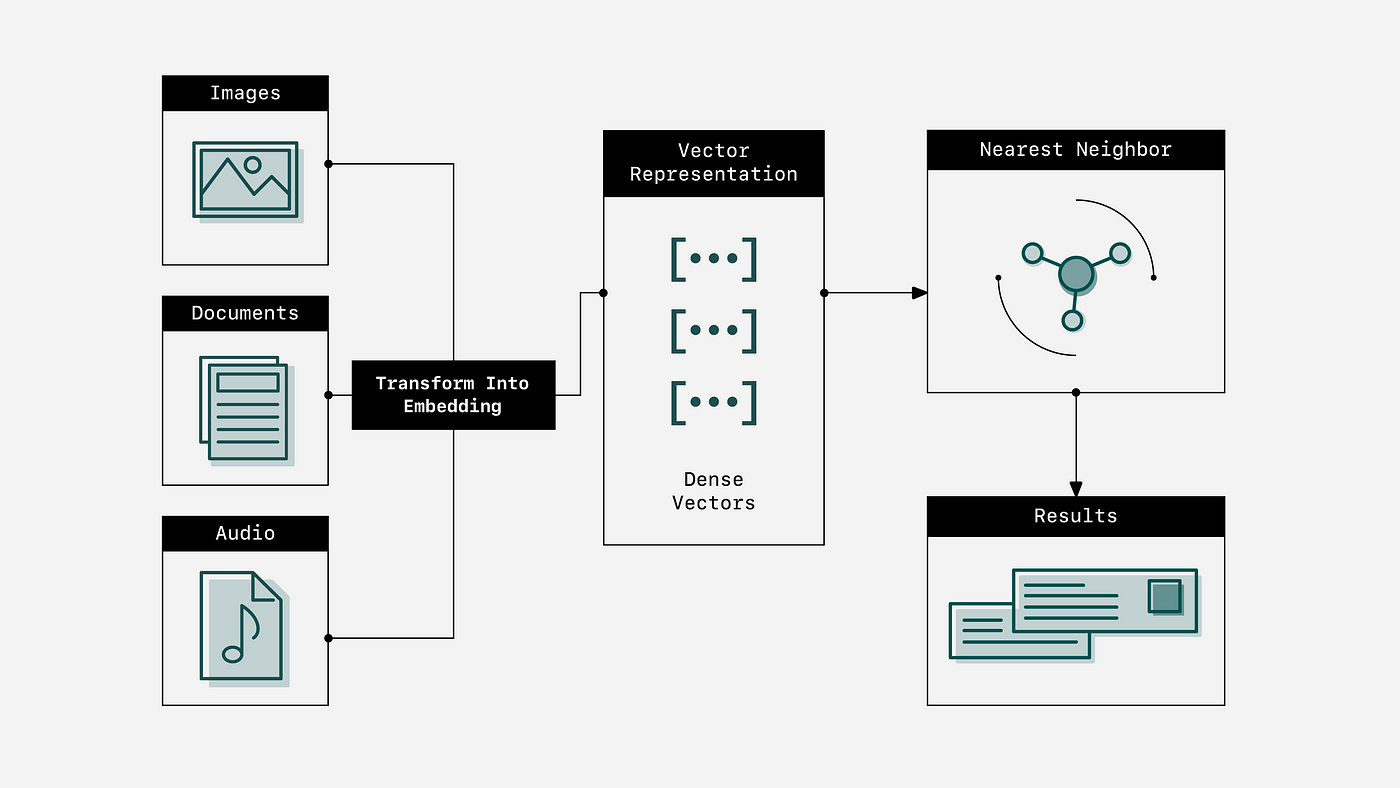
Below are few examples:
Word Embeddings: Word embeddings are a fundamental type of vector embedding that represents words as numerical vectors in a continuous space. They capture the semantic meaning and contextual relationships between words, enabling machine learning models to understand language and perform natural language processing tasks.

Word embeddings are widely used in applications such as sentiment analysis, language modeling, and document classification.
Image Embeddings: Image embeddings involve representing visual content, such as images or frames from videos, as numerical vectors. These vectors encapsulate the visual features and characteristics of the images, allowing machine learning models to analyze and process visual data. Image embeddings are essential for tasks such as image classification, object detection, and content-based image retrieval.
Document Embeddings: Document embeddings extend the concept of word embeddings to represent entire documents, such as paragraphs, articles, or books, as numerical vectors.
They capture the overall semantic content and context of the documents, enabling machine learning models to understand and compare large bodies of text. Document embeddings are valuable for applications like information retrieval, document clustering, and topic modeling.
Domain-Specific Embeddings: In addition to word, image, and document embeddings, there are various domain-specific embeddings tailored to specific applications and data types. These include user profile embeddings for capturing user preferences, product embeddings for similarity calculations in recommendation systems, audio embeddings for speech processing, and social network embeddings for analyzing social connections. Each domain-specific embedding is designed to capture the unique characteristics and relationships within its respective domain, empowering machine learning models to perform specialized tasks and analyses.
Methods and Techniques
Extracting and Representing Features
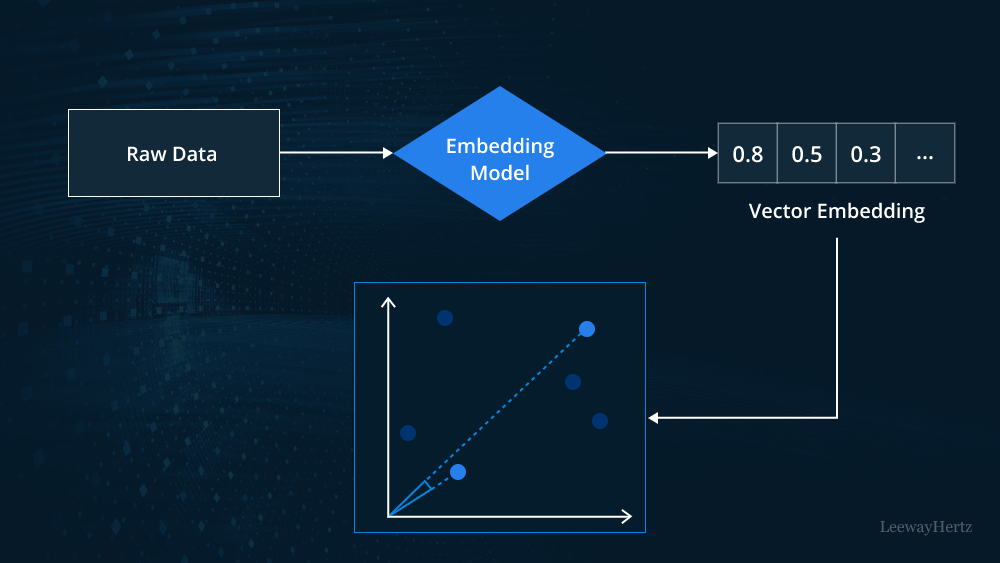
Feature extraction is a pivotal stage in the creation of vector embeddings, involving the identification of pertinent data attributes and their transformation into numerical features.
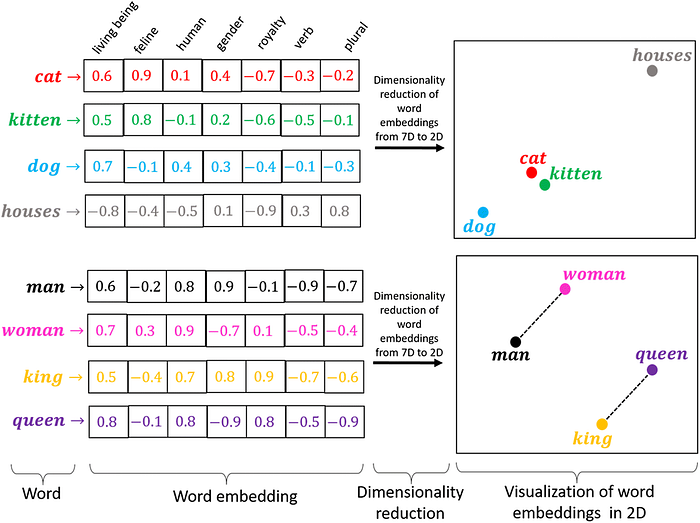
For example, in natural language processing, feature extraction involves identifying words, phrases, and semantic structures in text data and transforming them into numerical representations. This process enables the capture of semantic meaning and relationships between words, allowing machine learning models to understand and process language effectively. Similarly, in image processing, feature extraction involves identifying visual patterns, edges, and textures in images and converting them into numerical features, enabling the recognition of objects, scenes, and visual content in computer vision applications.
Reducing Dimensionality
High-dimensional data, such as images with a large number of pixels or text documents with numerous words, can pose challenges for machine learning algorithms. For example, in image processing, an image with a resolution of 1024x1024 pixels contains over a million individual pixel values, each contributing to the high dimensionality of the data. Similarly, in natural language processing, a document with a large vocabulary can result in high-dimensional word frequency vectors.
To address these challenges, dimensionality reduction techniques are employed.
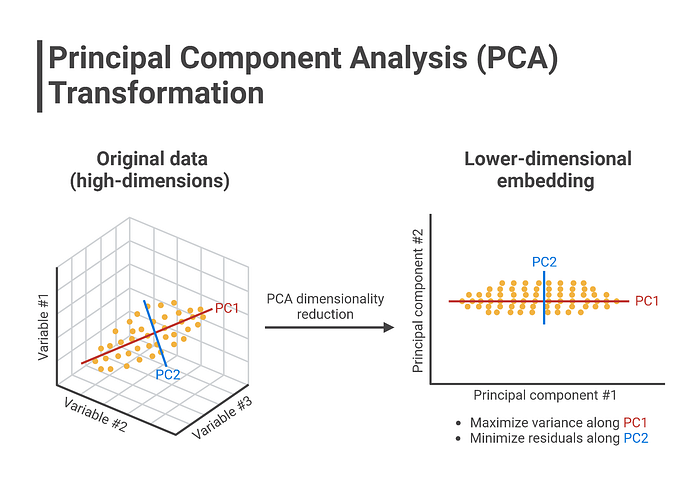
For instance, in image processing, techniques like Principal Component Analysis (PCA) can be used to reduce the dimensionality of image data while retaining essential visual features. This allows for efficient storage and processing of image data, making it easier for machine learning models to analyze and interpret visual content.
Calculating Similarity and Clustering
After obtaining embeddings, measuring similarity becomes crucial. For example, in natural language processing, cosine similarity is used to quantify the similarity between two text documents represented as vector embeddings.
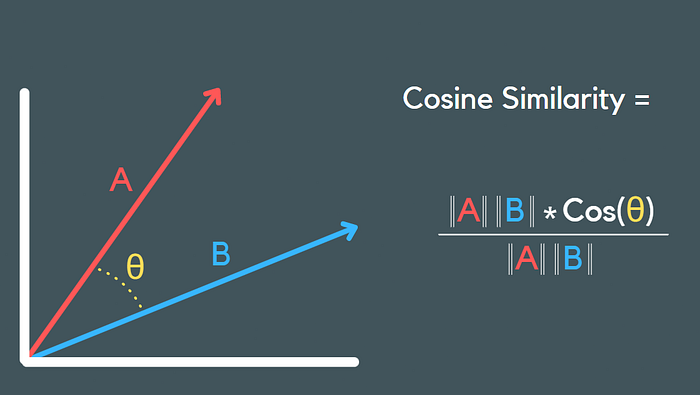
Cosine similarity measures the similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction. It is often used to measure document similarity in text analysis. —[4]
This method is essential for tasks such as document retrieval and clustering. In image processing, vector embeddings enable similarity calculations to identify visually similar images, aiding in content-based image retrieval and recommendation systems. Similarly, in recommendation systems, vector embeddings are used to measure similarity and provide personalized recommendations based on user preferences. These applications demonstrate the importance of vector embeddings in facilitating similarity calculations and clustering across various domains.
Applications of Vector Embedding
Natural Language Processing (NLP)
Text embeddings are integral to NLP tasks, with techniques like Word2Vec, BERT, and ELMo creating dense vector representations for words, sentences, or entire documents.
These embeddings enable:
Semantic similarity: Measuring the closeness of two pieces of text.
Named entity recognition: Identifying entities (e.g., names, dates) in text.
Sentiment analysis: Determining the sentiment (positive, negative, neutral) of a text.
Image Processing and Computer Vision
Image embeddings convert visual data into vectors, with Convolutional Neural Networks (CNNs) learning image embeddings by capturing features. Applications include:
Image similarity: Finding similar images based on their embeddings.
Object detection: Locating specific objects within an image.
Visual question answering: Using text and image embeddings to answer questions about images.
Recommendation Systems
Product embeddings enhance recommendation engines by representing items (e.g., movies, products) as vectors, enabling:
Personalized recommendations: Suggesting relevant products based on user preferences.
Collaborative filtering: Identifying similar users or items.
Information Retrieval and Search
Search engines leverage vector embeddings for efficient retrieval, with techniques like semantic search using embeddings to:
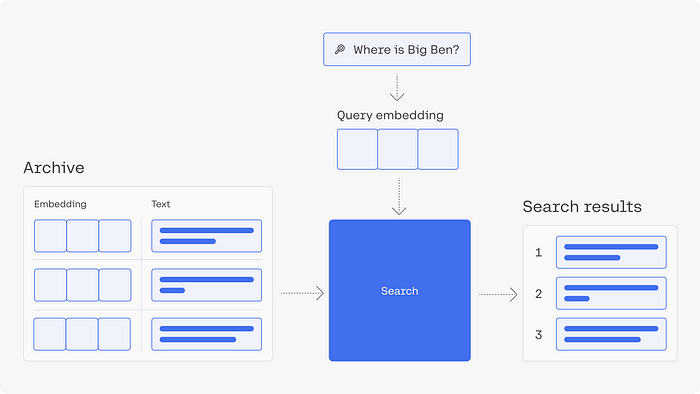
Understand user queries better. Retrieve relevant documents or web pages.
Document similarity: Comparing documents based on their embeddings.
How to create Embeddings?
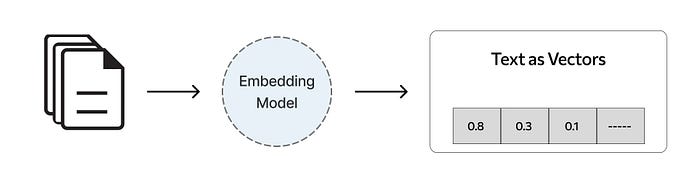
OpenAI’s embedding API provides a straightforward way to turn text into meaningful vectors.
Let’s dive into the process of creating embeddings using OpenAI:

To obtain an embedding, follow these steps:
Create an OpenAI API key — https://platform.openai.com/api-keys
Send your text string to the embeddings API endpoint.
curl -H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}' \
https://api.openai.com/v1/embeddings2. Specify the embedding model name (e.g., text-embedding-3-small)
OpenAI offers two powerful third-generation embedding models:
- text-embedding-3-small: 62,500 pages per dollar, 62.3% performance on MTEB evaluation.
- text-embedding-3-large: Higher performance, larger dimensions.
3. Extract the embedding vector from the response.
The response will contain the embedding vector along with some additional metadata.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
... (omitted for spacing)
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}4. Save it in a vector database for various use cases.
Conclusion
Vector embeddings are the foundation of AI, converting raw data into meaningful vectors for natural language processing, computer vision, recommendation systems, and search engines. They capture semantics, context, and relationships, shaping our digital interactions. Appreciating the role of vectors in AI advancements enriches our understanding of data representation and its impact on technology.
Do you want the article delivered directly to your inbox? Subscribe to my newsletter here — AI Stratus Insights or Subscribe on LinkedIn

References
- What are Vector Embeddings? | A Comprehensive Vector Embeddings Guide. (n.d.). Elastic. https://www.elastic.co/what-is/vector-embedding
- M, S. (2021, July 20). Feature Extraction and Embeddings in NLP: A Beginners guide to understand Natural Language Processing. Analytics Vidhya. https://www.analyticsvidhya.com/blog/2021/07/feature-extraction-and-embeddings-in-nlp-a-beginners-guide-to-understand-natural-language-processing/
- Perry, B. (2023, May 21). Dimensionality reduction. FinePROXY. https://fineproxy.org/wiki/dimensionality-reduction/
- Gomes, L. A. F., Da Silva Torres, R., & Côrtes, M. L. (2019, November 1). Bug report severity level prediction in open source software: A survey and research opportunities. Information & Software Technology. https://doi.org/10.1016/j.infsof.2019.07.009
- Markowitz, D. (2022, March 23). Meet AI’s multitool: Vector embeddings. Google Cloud Blog. https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
- OpenAI Platform. (n.d.). https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
